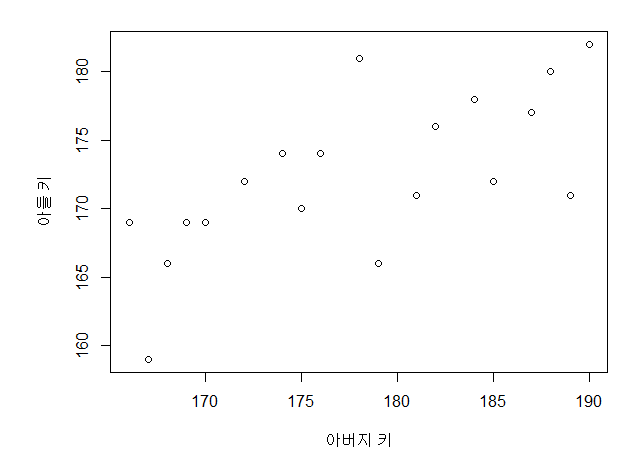
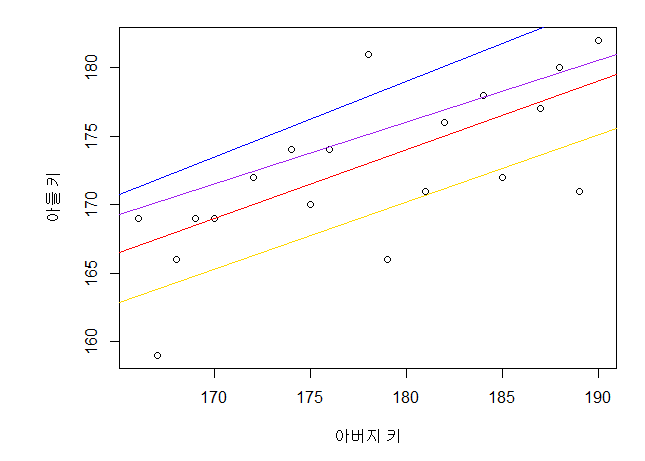
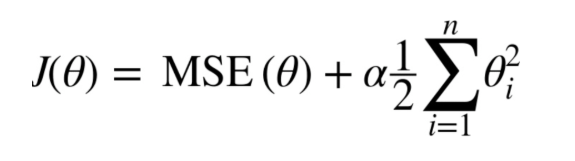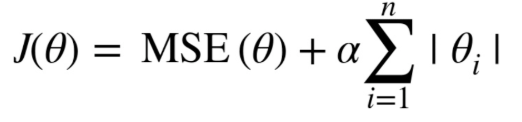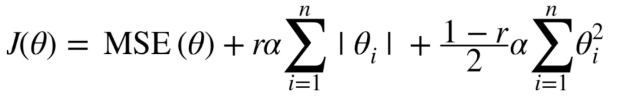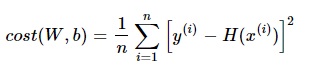우리가 지금까지 사용해온 Machine Learning Algorithm인 Linear Regression은
비용 함수인 mse를 최소화하는 방향으로 머신러닝 모델이 학습을 진행하게 된다.
하지만, 칼럼의 개수(독립변수의 개수)가 많아질수록 과적합될 가능성이 높아진다. 따라서,
어느 정도의 "규제"를 줌으로써 과적합되는 것을 방지하는 Ridge, Lasso가 등장하였고,
그 둘을 적절히 혼합하여 사용하는 ElasticNet이 등장하였다.
Ridge
릿지는, 기존 회귀분석의 비용함수에 어떠한 규제를 추가함으로써 진행된다.
다음과 같이 Beta_Hat 부분이 우리가 찾아야 할 점이라고 생각해보자.
회귀 함수의 MSE는 weight^2인 부분들의 미분 = 0인 부분을 찾아나가는 과정이다.
그런데, 최적점인 부분은 과적합될 가능성이 높기 때문에, Ridge를 통해 과적합이 되지 않도록 규제해준다.
원은 각각 세타1,세타2의 0,0을 중심으로 한 다고 생각하면,
타원과 원이 만나는 지점의 세타1, 세타 2의 값이 각각 해당하는 변수의 가중치가 되겠다.
이 가중치는 아래에서 설명할 LASSO처럼 0으로 만들지는 않지만, 중요하지 않은 변수를 0과 가깝게 만들어
줌으로써 과적합을 방지한다고 생각하면 된다.
LASSO
라쏘 또한 릿지와 마찬가지로 기존 회귀분석의 비용 함수에 규제를 추가하여준다.
릿지는 제곱값들의 합, 라쏘는 절댓값들의 합 규제가 각각 추가된다고 생각하면 된다.
절댓값인 점을 통해, 다음과 같이 마름모 형태로 LASSO의 세타들은 표현되게 되고, 최적의 비용 함수 mse는 점차 그 값을 늘려가면서 LASSO와 만나는 점에서 멈춘다. 만나는 지점을 보면, 베타 1이 0인 지점에서 만나게 되어, 베타 1을 상수항으로 갖는 변수는 0이 되어 변수가 회귀에 끼치는 영향이 0이 되게 된다.
이에 따라, LASSO를 필요 없는 변수를 제외시키기 위해서도 종종 사용된다고 한다.
ElasticNet
엘라스틱 넷은 위에서 보았던 Ridge와 Lasso를 적절히 사용하여 회귀식을 규제한다.
Ridge, Lasso 모두 시그마 앞에 알파 값을 통해 규제 정도를 얼마나 줄지 조절해 줄 수 있다.
파이썬 sklearn의 Ridge와 Lasso 알고리즘에는 알파에 해당하는 Hyperparameter가 존재, 그 값을 조정함으로써
"Multiple regressions are based on the assumption that there is a linear relationship between both the dependent and independent variables. It also assumes no major correlation between the independent variables."
다중회귀분석은 조금 다르다.
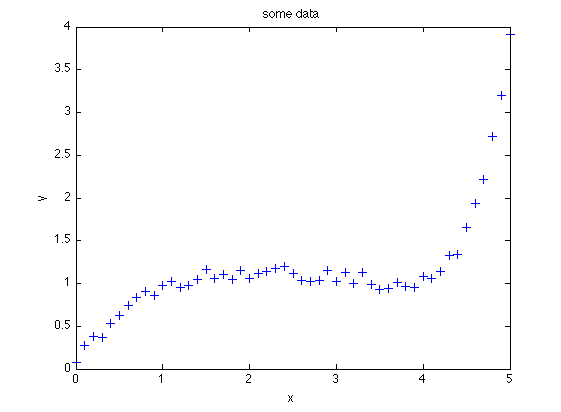
선형적인 특성을 띄지 않는 데이터를 생각해보자.
다음과 같은 데이터는 아무리 직선을 잘 그어도, 이 데이터를 설명하는 직선으로는 살짝 부족한것이 보일 것이다.
데이터를 자세히보면, 3차식에는 뭔가 잘 맞을 것 같아 보인다.
이렇게, 데이터의 형태에 따라서 (선형으로는 안될것같을때(??))
polynomial regression을 해주면, 조금 더 높은 정확도를 얻어낼 수 있다.
하지만, 차수를 높일수록, 주어진 데이터에 overfitting이 될수 있음을 항상 염두해 두어야한다.
예를들어, 저 그래프를 차수를 높여서 y = wx^3으로 그리면 조금더 맞는(?)그래프를 그릴 수 있을 것 같다.
결국 회귀분석의 이론은 다 같다. 그러나, 변수의 형태, 개수에 따라서 그것들이 나누어 지는 것같다.