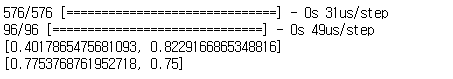https://wingnim.tistory.com/47
U-Net 논문 내용 정리 및 설명
이번에 정리할 논문은 의료 영상/이미지 segmentation에서 많이 쓰이는 모델 구조의 시초가 된 U-Net : Convolutional Networks for Biomedical Image Segmentation 이다. U Net 은 , 단순히 이미지를 classificat..
wingnim.tistory.com
https://mylifemystudy.tistory.com/87
U-Net 정리 (U-Net: Convolutional Networks for Biomedical Image Segmentation)
U-Net: 바이오메디컬 이미지 세그멘테이션을 위한 컨볼루셔널 네트워크 메디컬 이미지 Segmentation 관련해서 항상 회자되는 네트워크 구조가 U-Net 이다. End-to-End 로 Segmentation하는 심플하고 효과적인 방법..
mylifemystudy.tistory.com
https://dacon.io/competitions/official/235591/codeshare/915?page=1&dtype=recent
AI프렌즈 시즌2 위성관측 활용 강수량 산출 대회
출처 : DACON - Data Science Competition
dacon.io
dacon 강수량 산출 대회
딥러닝을 위한 Atrous Convolution과 U-Net 구조: 간략한 역사
원문: Atrous Convolutions and U-Net Architectures for Deep Learning: A Brief History https://blog.exxactcorp.com/atrous-convolutions-u-net-architectures-for-deep-learning-a-brief-history/ 딥러닝의..
www.quantumdl.com
object detection 관련 링크
https://bskyvision.com/465?category=615305
물체 검출 알고리즘 성능 평가방법 AP(Average Precision)의 이해
물체 검출(object detection) 알고리즘의 성능은 precision-recall 곡선과 average precision(AP)로 평가하는 것이 대세다. 이에 대해서 이해하려고 한참을 구글링했지만 초보자가 이해하기에 적당한 문서는 찾기..
bskyvision.com
'Data Anaylsis > Deep Learning' 카테고리의 다른 글
| keras ImageDataGenerator (0) | 2020.03.20 |
|---|---|
| 딥러닝 3일차 (0) | 2020.03.18 |
| 딥러닝 2일차 (0) | 2020.03.17 |
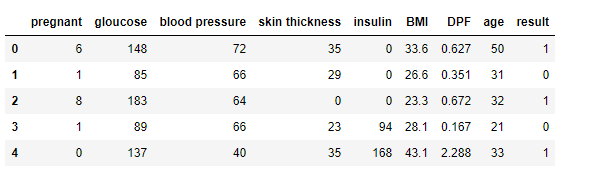
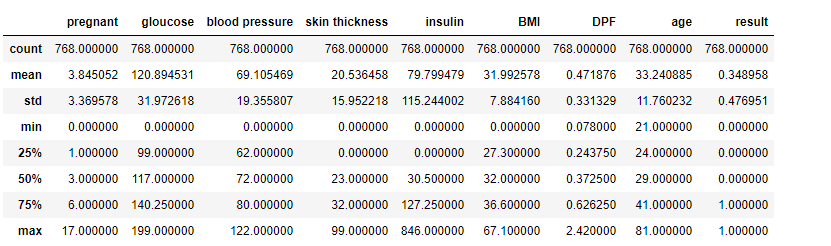
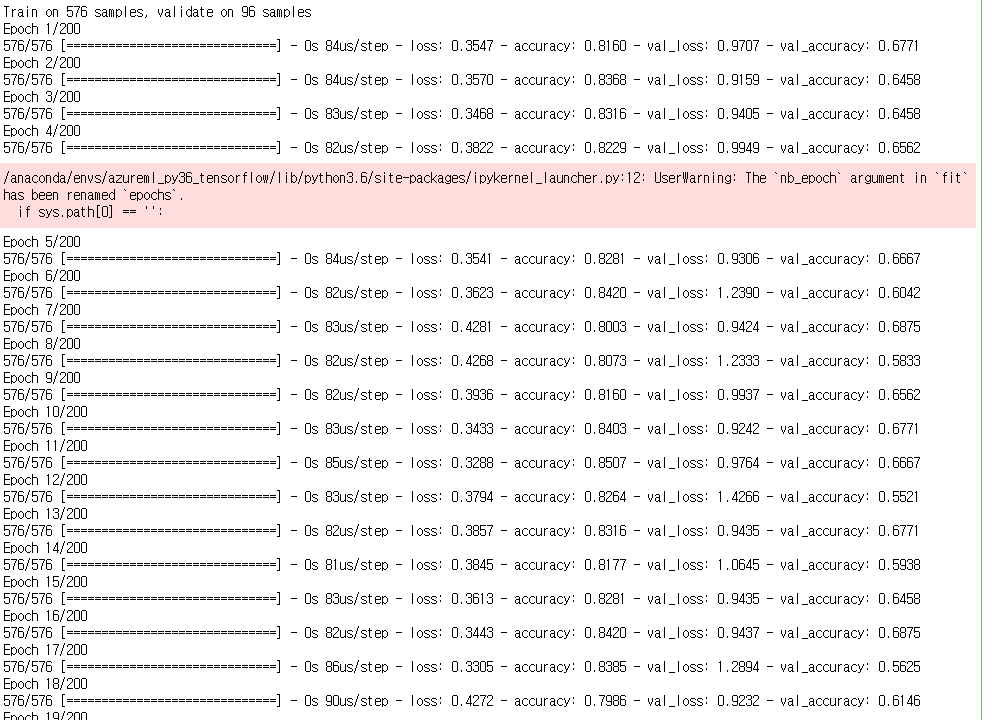
| Keras 모델 생성/학습 - 당뇨병 예측 모델 (0) | 2020.03.16 |
| AND,OR/XOR 문제 keras로 구현! (0) | 2020.03.16 |