데이터 처리
# 1. Pandas 가져오기
import pandas as pd
# 2. 데이터 불러오기
data = pd.read_csv('diabetes_data.csv')
data.head()
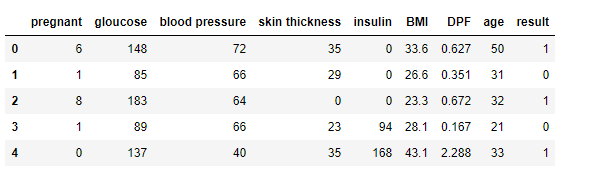
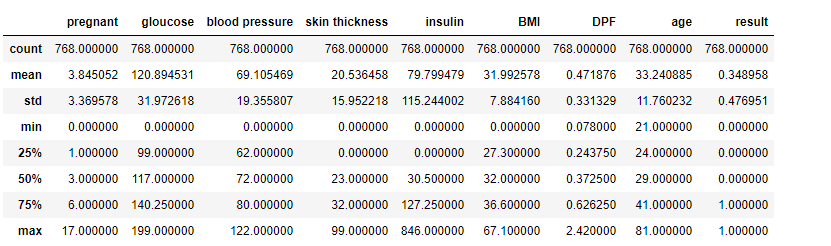
# 데이터 통계치 확인하기
data.describe()
# 3. X/y 나누기
X = data.iloc[:,:-1].values
y = data.iloc[:,-1].values
# values를 붙여서 numpy array형태로 가져온다!!!!! 매우 중요하다!!!! 큰 깨달음
print(X.shape)
print(y.shape)
# 4. Train set, Test set 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_test,y_test,
test_size=0.5,
random_state=19)
print(X_train.shape)
print(X_val.shape)
print(X_test.shape)
print(y_train.shape)
print(y_val.shape)
print(y_test.shape)
Keras 모델 만들기
# 5. Keras 패키지 가져오기
from keras.models import Sequential
from keras.layers import Dense

# 6. MLP 모델 생성
model = Sequential()
model.add(Dense(units=64, input_dim=8, activation='relu'))
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
model.summary()

# 7. Compile - Optimizer, Loss function 설정
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 8. 학습시키기
from keras.callbacks import EarlyStopping, ModelCheckpoint
early_stop = EarlyStopping(patience=20)
batch_size = 32
epochs = 200
history = model.fit(X_train,y_train,
batch_size=batch_size,
nb_epoch=epochs,
validation_data=(X_val,y_val),
callbacks=[early_stop],
verbose=1
)
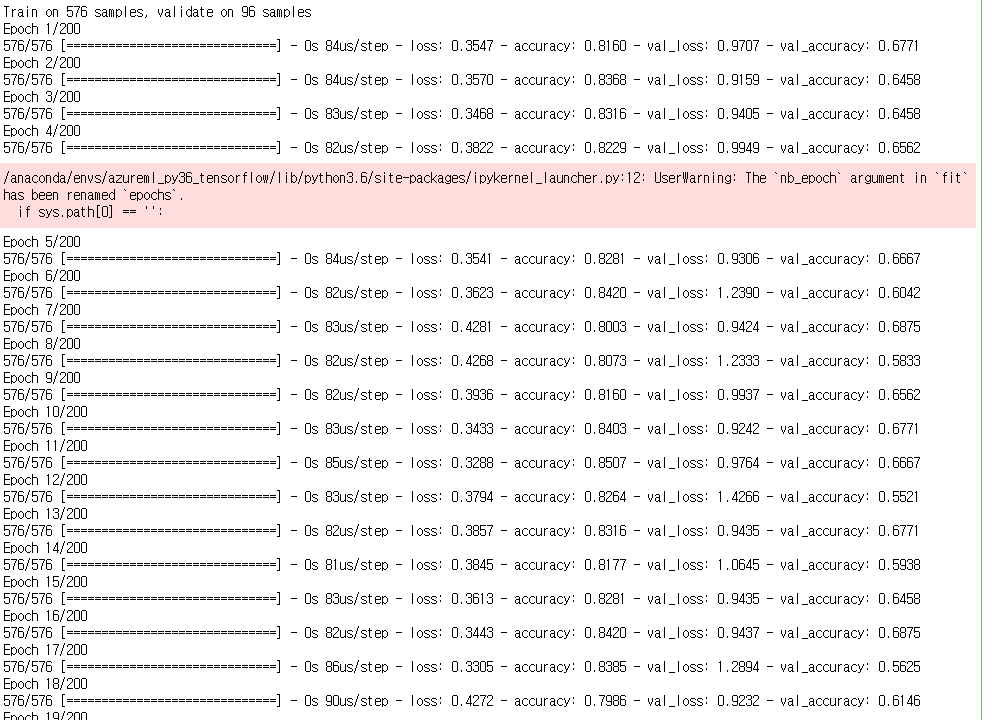
# 9. 모델 평가하기
train_acc = model.evaluate(X_train,y_train)
test_acc = model.evaluate(X_test,y_test)
print(train_acc)
print(test_acc)
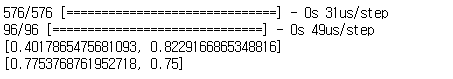
시각화
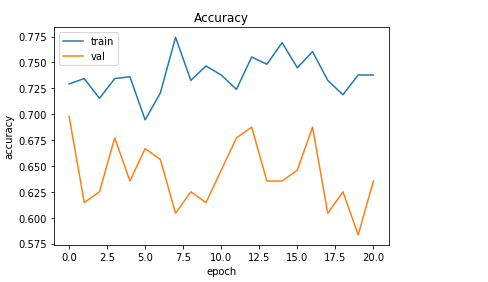
# 10. 학습 시각화하기
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['train','val'], loc = 'upper left')
plt.show()
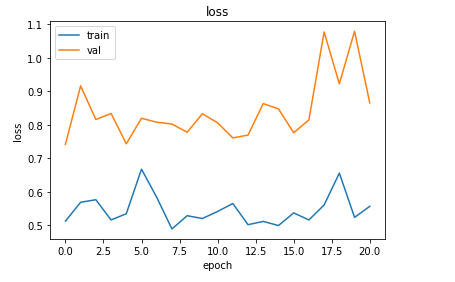
# loss 값 그래프 그리기
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'], loc = 'upper left')
plt.show()
# 11. 모델 저장
model_path ='diabet_model.h5'
model.save(model_path)
# 12. 모델 불러오기
from keras.models import load_model
loaded_model = load_model(model_path)
print(loaded_model.summary())
