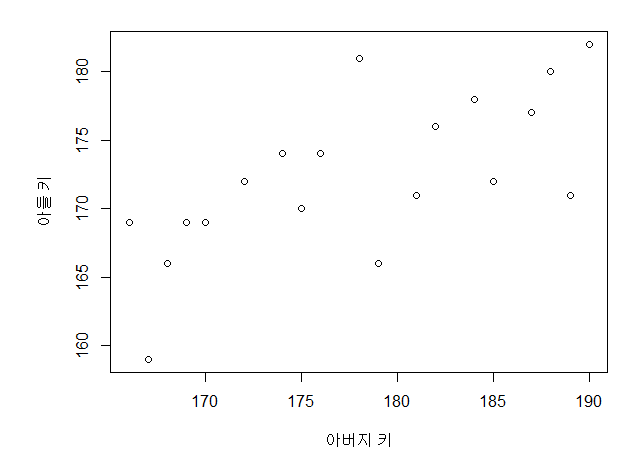
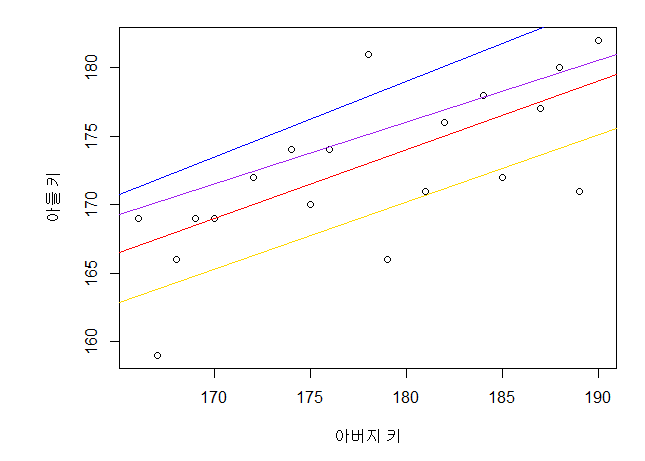
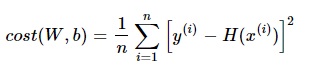Single Linear Regression,
Multiple Linear Regression,
Lasso, Ridge,
Polynomial Regression,
----------------------------------------------
random forest
앙상블
kmeans : 초기 k개의 중심점을 랜덤으로 잡아서 중심점과 점들 사이의 오차를 줄여나가는 방향으로
더이상 중심점이 움직이지 않을때까지 중심점을 이동시키며 k 개로 군집을 형성한다.
bisecting kmeans : K means의 문제점을 살짝 개선시킨 것으로,
hierarchical clustering과 k means의 합성으로 보면 좋다.
처음 1개의 중심점에서 2개의 sub clustering으로 나아가는 방향으로 클러스터 갯수를 계속 늘려간다.
K를 몇으로 잡느냐에 따라 클러스터의 갯수가 정해진다.
이 클러스터는 k means의 문제점인 어떠한 클러스터에는 빈값을 가질 수 도 있기 때문에 그 점을 개선시키기 위해
계층적 군집화를 바탕으로 k means를 하는 것이다.
Scaling: Keep in mind that in order to implement a PCA transformation features need to be previously scaled.
Note: The main issue with "Random Under-Sampling" is that we run the risk that our classification models will not perform as accurate as we would like to since there is a great deal of information loss (bringing 492 non-fraud transaction from 284,315 non-fraud transaction)
Correlation Matrices
Correlation matrices are the essence of understanding our data. We want to know if there are features that influence heavily in whether a specific transaction is a fraud. However, it is important that we use the correct dataframe (subsample) in order for us to see which features have a high positive or negative correlation with regards to fraud transactions.
Note: We have to make sure we use the subsample in our correlation matrix or else our correlation matrix will be affected by the high imbalance between our classes. This occurs due to the high class imbalance in the original dataframe.
Anomaly Detection:
Our main aim in this section is to remove "extreme outliers" from features that have a high correlation with our classes. This will have a positive impact on the accuracy of our models.
Interquartile Range Method:
- Interquartile Range (IQR): We calculate this by the difference between the 75th percentile and 25th percentile. Our aim is to create a threshold beyond the 75th and 25th percentile that in case some instance pass this threshold the instance will be deleted.
- Boxplots: Besides easily seeing the 25th and 75th percentiles (both end of the squares) it is also easy to see extreme outliers (points beyond the lower and higher extreme).
Outlier Removal Tradeoff:
We have to be careful as to how far do we want the threshold for removing outliers. We determine the threshold by multiplying a number (ex: 1.5) by the (Interquartile Range). The higher this threshold is, the less outliers will detect (multiplying by a higher number ex: 3), and the lower this threshold is the more outliers it will detect.
The Tradeoff: The lower the threshold the more outliers it will remove however, we want to focus more on "extreme outliers" rather than just outliers. Why? because we might run the risk of information loss which will cause our models to have a lower accuracy. You can play with this threshold and see how it affects the accuracy of our classification models.
-----------------------------------------------------------------------------------------------------------------------------------
앙상블
전체적인 어울림이나 통일, 조화
성능이 별로 좋지 않은 모델들을 이용해서
하나의 모델만을 사용할때보다 더 좋은 결과를 보여준다
투표기반분류기()
직접투표(민주적인 투표)
다수결의 투표
간접투표는 확률을 이용해서 더 높은 확률이 나온 모델을 사용한다.
확률이 높은 모델에 더 비중을 들수 있기 때문에 더 좋다.
모델도 다양한 모델들을 사용할 수록 좀 더 일반화된 결과를 보여줄 수 있다.
앙상블은 그럼 갯수를 늘릴 수록 더 좋은것인가? --
0.5보다는 높아야된다.
배깅 앤드 페이스팅
샘플을 여러번 뽑아 각 모델을 학습시켜 결과를 집계
배깅은 중복 허용, 페이스팅은 중복 불가
배깅을 사용하면 오버피팅을 막을 ㅅ 있다.
out of bag 평가 63프로정도만 사용되고 37퍼정도는 남아있게 된다.
검증셋, 교차 검증에 사용해서 배깅 성능 측정을 위한 좋은 지표가 된다.
검증을 위해 데이터를 따로 빼놓는것이
교차검증 - 오버피팅을 방지하기 위해서
랜덤포레스트
각각의 트리들은 독립적으로 생성하게 되고, 랜덤 샘플해서 피쳐또한 모두 사용하지 않고,
피쳐도 랜덤으로 선택한다.
소프트 투표를 쓴다 + 배깅을 쓴다
중요한 매개변수 n-estimators, max-features
(default값을 사용하는 것이 좋다.) 모델이 돌아가면서 스스로 최적의 갯수를 찾아낸다.
부스팅 -
여러개의 모델들을 연결 시켜서 더 좋은 모델을 만드는 앙상블 학습 방법이다.
아다부스트는
데이터가 잘 학습되지 않는 곳에 가중치를 주어 모델의 성능을 향상시킨다.
그래디언트 부스팅
잔여 오차에 대해 새로운 모델을 학습시키는 방법이다.
잔여오차를 데이터로 또 만들어서 그 오차에대한 모델을 학습시켜서
확인하면 좋은 매개변수 : learning rate, n_estimator(여기서 모델의 갯수는 잔여오차 모델의 갯수인가)
early stopping 잘씀
stacking (?)
잘모르겠다.
-----------------------------------------------------------------------------------------------------------------------------------
데이터베이스를 왜 설명하냐?
창고같은거다.
비지도학습
(파라미터)
ㅇ
-----------------------------------------------------------------------------------------------------------------------------------
의사결정나무 설명력이 없다? (X)
SVM 초평면
-----------------------------------------------------------------------------------------------------------------------------------
데이터 전처리
데이터 품질이란 신뢰성을 의미
잡음이 많이 포함되는 경우, 오버피팅이 발생할수 있으며 일반화가 어렵다.
이상치 일반적인 데이터인데 기존 범주를 살짝 벗어나는 것이다.
결측치
데이터 수집
데이터 정제
결측치가 몇퍼센트가 없으면 버리는게 좋고, 너무 많으면 대체를 하는건가?
noise 제거 방법 (잘모르겠음)