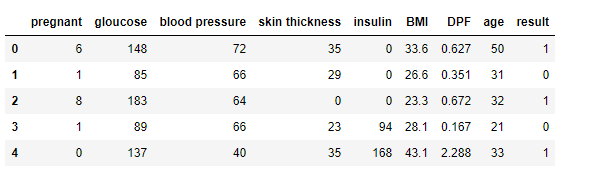
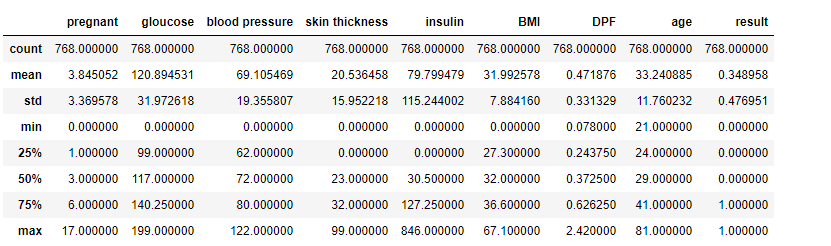
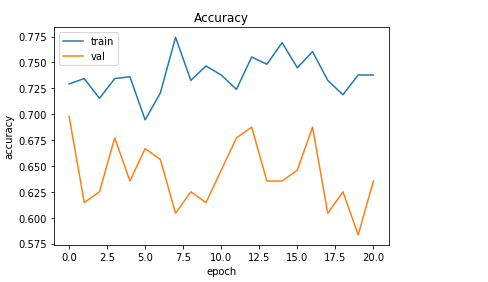
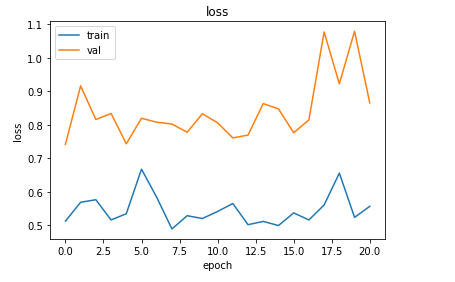
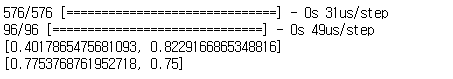선형 회귀분석의 기초라고 할 수 있는 단순 선형 회귀분석이다.
머신러닝에 있어서 정답 레이블이 연속형인 값을 예측하는 데 사용된다.
예를 들어보자.
아버지의 키를 통해 아들의 키가 몇이 될지 예측하고 싶다.
<여기서 아버지의 키는 X변수(독립변수, feature), 아들의 키는 Y변수(종속변수, label)이다.>
데이터로 몇 명의 아버지와 몇명의 아들의 키를 가지고 있다.
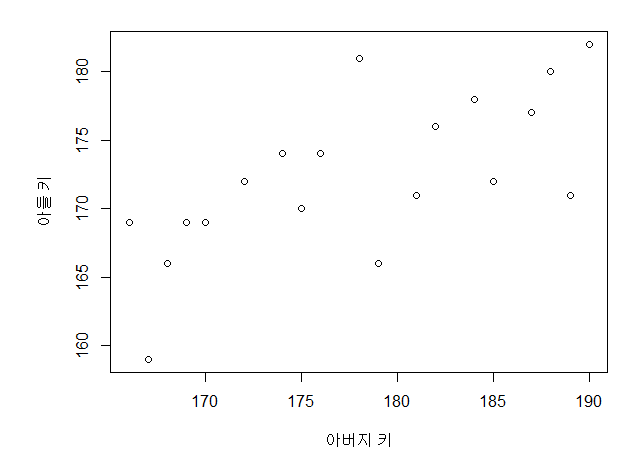
다음과 같이 아버지의 키와 아들의 키를 scatter로 뿌려보면 다음과 같이 보일 것이다.
그러면 우리는 아버지의 키와 아들의 키를 잘 설명할 수 있는 직선을 그을 수 있다.
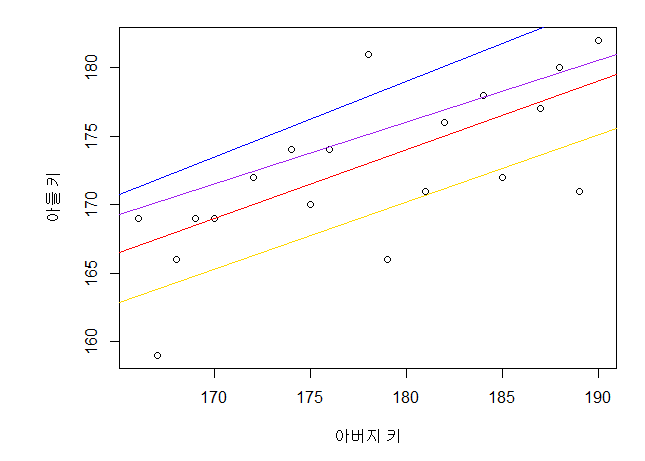
다음과 같이 여러 직선을 그은 것 중에, 점(실제 데이터)과 예측(점과 X값이 같으면서 선위의 점) 사이의 거리(cost)가
최소가 되는 점이 아버지의 키와 아들의 키를 가장 잘 설명하는 직선이 될 것이다.
왜 우리는 이러한 선을 긋고,
예측을 하려는 것일까?
머신러닝의 기본으로 다시 돌아와 보면,
데이터가 풍부해짐에 따라
가지고 있는 데이터를 통해
새로운 데이터를 맞이 했을 때, 그 값을 미리 예측할 수 있다면,
어떠한 서비스를 예측하여 제공해 줄 수도 있고,
기후 예측 등 실생활에서 활용을 할 수 있다.
이 예제에서도 마찬가지로, 아버지의 키를 통해 아들의 키가 어떻게 변화하는지를 보면서
아버지의 키와 아들의 키가 관계가 있다는 인사이트를 도출할 수 있다.
다시 본론으로 돌아오면, 이러한 점과 선 사이의 거리는 제곱의 형태나 절댓값의 형태로 나타낼 수 있다.
제곱을 다 더한 것이 우리가 자주 듣던 MSE(Mean Squared Error, 평균 제곱 오차)이고,
절댓값을 다 더한 것이 MAE(Mean Absolute Error, 오차절대합)이다.
결국, 점-선 또는 선-점을 합해버리면 그 값들이 상쇄가 되어 제곱이나 절댓값 형태를 취해주어서
상실되는 것을 방지하는 것이다.
여기서 제곱을 한다면, 에러가 크게 날 수록, 그 에러에 대해 제곱을 하게 되면 더 크게 값이 형성된다.
제곱 형태를 사용하면, 많이 벗어난 에러애 대해 큰 벌점을 주게 되는 것이다.
이러한 경우, 이상점이 있다면 error가 높을 것이라는 추측을 할 수 있다.
MSE를 활용하여 cost함수를 최소화 하도록 해보자.
수식적으로 간단하게 접근해보자.
저 아버지와 아들의 관계를 나타낸 선을 y = wx + b라고 한다면,
y와 x의 관계를 잘 설명하는 최적의 w와 b를 구하는 것이 목표인 것이다.
여기서
y는 우리가 예측할 값이므로 H(x)로 표현할 수 있다.
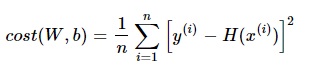
이러한 과정을 Gredient Decesnt, 경사하강법이라고 부른다.
이를 수식적으로 표현해보면, 다음과 같은 cost 식을 도출해 낼 수 있다. 우리는 이 cost(W,b)를 최소화하는 것이 목적이다.

위의 식에서 H(x)자리에 wx+b를 대입하고, 식을 푼다면 이 식은 W에 대한 2차방정식으로 표현될 수 있다.
(나머지 문자는 상수 취급)
그러면 우리는 2차방정식을 그래프(2차함수, 아래로볼록)을 그릴 수 있고,
X축은 W축, Y축은 COST축이라고 말할 수 있다.
이 cost가 가장 작은 지점은 이차함수에 있어서 미분된 값(기울기)가 0이 되는 지점일 것이다.
그 값을 구하기 위해 W미분값이 최소가 되는 값을 구하는 과정이 바로 Gredient Decent의 핵심 아이디어이다.
기존 가중치 - 알파(learning rate, 학습률) * W를 미분해서 나온 값 * cost(W)값 을 진행하면서
W의 값을 계속 업데이트 해나가며, 더이상 W가 움직이지 않을때, 그 지점이 바로 cost의 최솟값, w의 최적값이 되는 것이다.

여기서 알파값(learning rate)을 어떻게 잡느냐에 따라 W가 움직이는 속도가 정해진다. learning rate 값이 클수록 W는 크게크게 바뀌게될 것이고, learning rate 값이 작을수록 천천히 접근하게 될 것이다.
이를 잘 맞춰 주어야한다.
단순선형회귀의 기본적인 개념은 여기까지다.
질문이 있으시다면 댓글에 적어주시면
성실히 답변해드리겠슴다.