안녕하세요~ 보나에요!
오늘은 centos7 에 파이썬 가상환경을 설치 해볼 거에요!!
가상환경을 설치하면.. 다양한 이점들이 있어요
1. python 버전
2. library 버전
등..
버전차이로 인해 발생하는 우리들..
A라는 모듈을 사용하기 위해서 X_1.0, Y_2.0 버전이 필요하다고 생각해볼께요!
만약,
B라는 모듈을 사용하고 싶어졌어요! 근데 이 모듈은 X_1.1, Y_2.1버전이여야지 돌아간대요..
그러면 X_1.0,Y_2.0 을 uninstall 하고 새로운 버전으로 깔아야해요..
이렇게 자주 그러다보면 사람이 미치고 팔짝뛰는거죠잉..
그래서 가상환경을 깔아서! 필요한 모듈들만 싹싹! 가져오면!!
효율적으로 관리할 수 있을것 같아요!!
그럼 이제 한번 깔아 봅시다!!
sudo pip install virtualenv
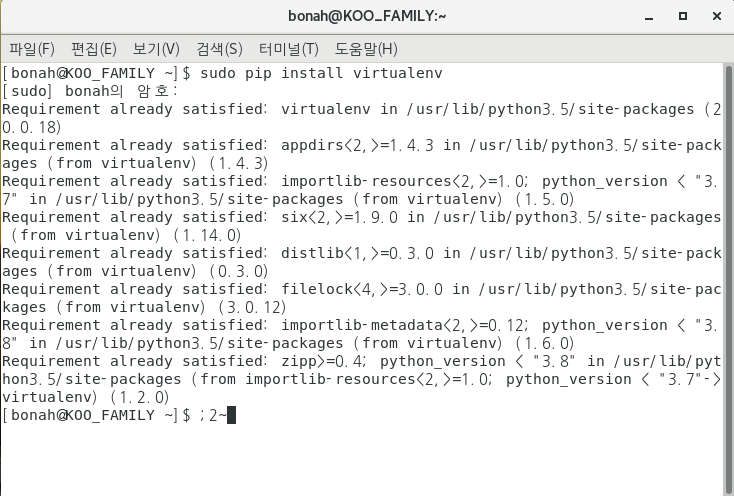
pip 명령어를 통해 virtualenv(가상환경)을 설치해줍니다!! 저는 이미 깔려져 있어서.. ㅎㅎ
그럼 이제! 가상환경으로 만들어줄 폴더를 하나 만들어 봅시다!
저는 제 디렉토리 아래에 하나 만들어보려고해요
mkdir env2

env2 라는 파란 글씨를 보실 수 있어요! (파랑글씨는 디렉토리, 검정글씨는 파일을 의미해요! 참고!!)
그럼 이제 env2라는 폴더를 가상환경 폴더로 지정해줄 수 있어요!
virtualenv env2
cd env2 ls -l
env2 폴더 디렉토리 를 보시면
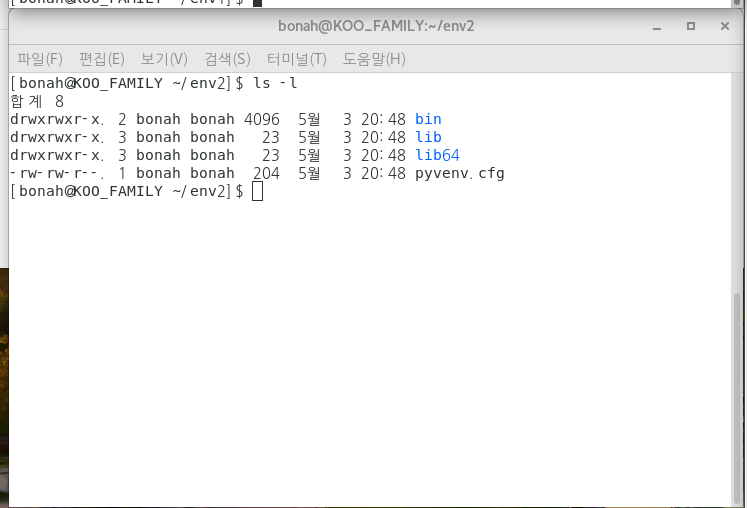
다음과 같이 생성되었음을 확인할 수 있어요!!
그리고 여기서 가상환경을 실행해 볼게요!
source ./bin/activate
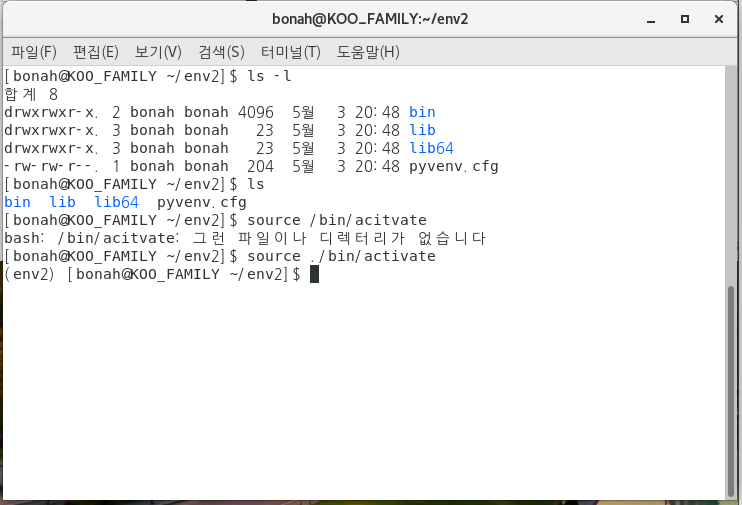
저는 지금 env2 디렉토리가 지금 제 현재 디렉토리이기 때문에 ./bin/activate 만으로 가능했지만,
제일 안전한 방법은 절대경로를 모두 입력해 주는것이 좋아요!!
Anyway,,,
그럼 이제 env2 가상환경 속으로 들어온거에요 !! 예~~~~
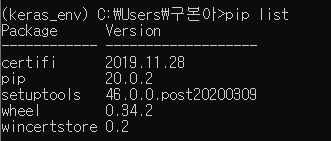
여기서 한번 확인을 해볼게요. pip list (pip로 install 한 library 목록 리턴)
python 쳐서 어떤 파이썬이 설치되어있는지
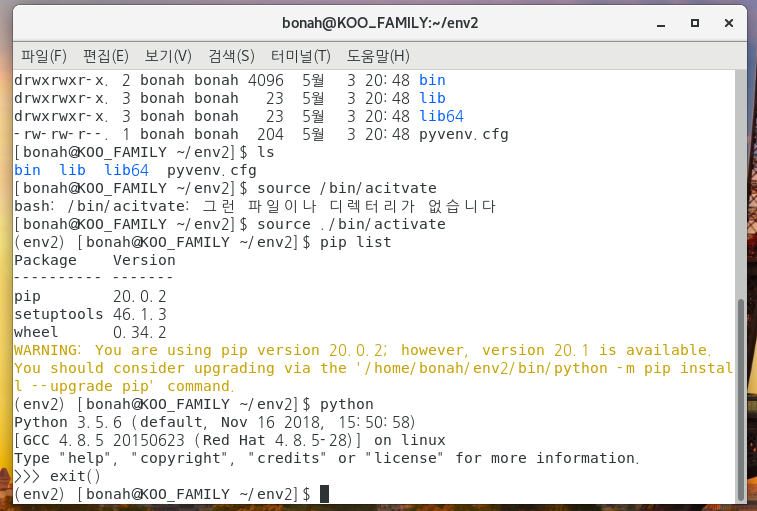
pip 라이브러리도 깨끗하고, python은 3.5.6버전이 깔려있는걸 확인할 수 있었습니다~~짝짝짝~~~
다시 나가는 방법은
deactivate
이라고 작성하시면 가상환경에서 빠져나옵니다!
큰일났어요
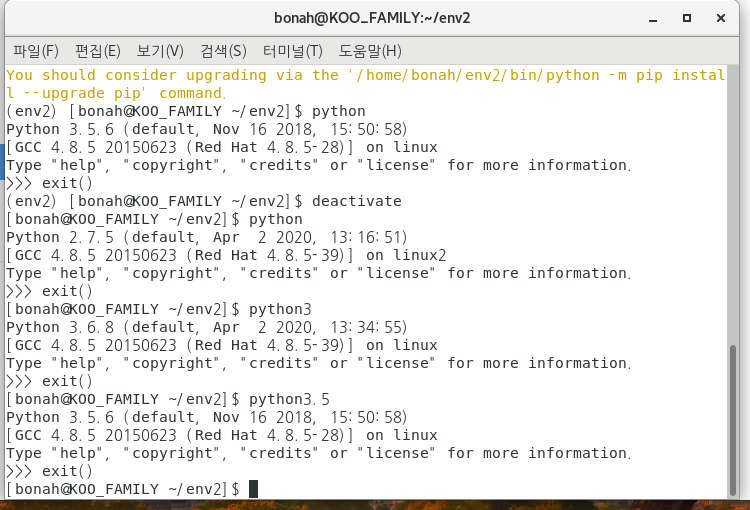
이것저것 만지다 보니 다양한 파이썬들이 깔렸는데... 이걸 어떻게 처리해야할 지 모르겠어요..
다양한 작업을 하다보니... 휴... 언젠가 다 알아내서 다 정리해 내고 말거에요.. ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
일단 여기까지는 가상환경 설치해 보기였습니다~
'OS > Linux' 카테고리의 다른 글
| transfer files from window to linux (0) | 2020.08.13 |
|---|---|
| linux(centos7) 명령어 모음 (0) | 2020.04.30 |
| centos7에서 python2, python3 모두 사용하기 (0) | 2020.02.09 |
| 2020_0123 (0) | 2020.01.23 |