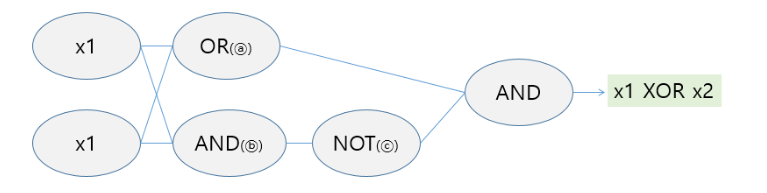
AND 문제
# 1. Numpy 가져오기
import numpy as np
print(np.__version__)import keras
print(keras.__version__)# 3. Keras 패키지 가져오기
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.optimizers import SGD# 2. 입력/출력 데이터 만들기
X = np.array([[0,0],[0,1],[1,0],[1,1]])
y = np.array([[0],[0],[0],[1]])# 4. Perceptron 모델 생성
model = Sequential()
model.add(Dense(units=1, input_dim=2, activation='sigmoid'))
model.summary()
# 5. Compile - Optimizer, Loss function 설정
sgd = SGD(lr=0.1)
model.compile(loss='binary_crossentropy',
optimizer=sgd)# 6. 학습시키기
model.fit(X,y, batch_size=1, nb_epoch=500)# 7. 모델 테스트하기
test = np.array([[0,1]])
pred = model.predict(test)
print(pred)[[0.09028968]]
print(model.get_weights())[array([[4.248023 ], [4.2462897]], dtype=float32), array([-6.5563927], dtype=float32)]
OR 문제
X = np.array([[0,0],[0,1],[1,0],[1,1]])
Y = np.array([[0],[1],[1],[1]])model = Sequential()
model.add(Dense(1, input_dim=2, activation='sigmoid'))model.summary()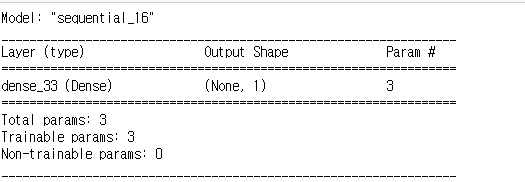
sgd = SGD(lr=0.1)
model.compile(loss='binary_crossentropy', optimizer='sgd')
model.fit(X,Y, batch_size=1, nb_epoch=100)test = np.array([[1,1]])
model.predict(test)array([[0.9742955]], dtype=float32)
XOR 문제
X2 = np.array([[0,0],[1,0],[0,1],[1,1]])
Y2 = np.array([[0],[1],[1],[0]])model_2 = Sequential()
model_2.add(Dense(units=16,input_dim=2, activation='relu'))
model_2.add(Dense(units=1, activation='sigmoid'))
model_2.compile(loss='binary_crossentropy',optimizer=sgd)
model_2.fit(X2,Y2, batch_size=1, nb_epoch=200)test = np.array([[0,0],[1,0],[0,1],[1,1]])
pred = model_2.predict(test)
print(pred)
'Data Anaylsis > Deep Learning' 카테고리의 다른 글
| 딥러닝 3일차 (0) | 2020.03.18 |
|---|---|
| 딥러닝 2일차 (0) | 2020.03.17 |
| Keras 모델 생성/학습 - 당뇨병 예측 모델 (0) | 2020.03.16 |
| Deep learning 1일차 (0) | 2020.03.16 |
| conda 가상환경 설치 (1) | 2020.03.13 |